
2023 PhD thesis
Compact and Progressive Encodings for Task-Adaptive Queries of Scientific Data
As computational power outpaces bandwidth, handling multi-petabyte datasets, which are easier to produce than
to store or access, becomes a challenge. Traditional solutions focus on data reduction through lossy
compression or downsampling, but many overlook considerations like the scientific tasks to be performed on the
data or the computational resources required. Additionally, there’s a lack of a common framework to gauge
these techniques’ efficacy and costs. This dissertation introduces such a framework and presents novel data
reduction techniques offering more holistic considerations and compelling trade-offs.
A novel hierarchical data model that unifies spatial resolution and numerical precision is developed. Most
current reduction techniques focus on either resolution or precision, but this new model allows for
approximations anywhere in the 2D space of resolution and precision, offering refined approximation in either
axis without necessarily refining the other.
A novel progressive streaming framework is proposed to study trade-offs between reducing resolution and
precision during common analysis tasks. Using the wavelet transform, both resolution and precision-based
reduction techniques can be modeled as different orderings of wavelet coefficient bits. This enables the
first-ever demonstration that reducing both resolution and precision is significantly more effective than
reducing either alone. It further allows the optimization of bit streams for specific analysis tasks, offering
insights about how different tasks fetch data.
Lastly, the new data model is adapted to encode unstructured particle data, a common form of data
representation in scientific simulation or imaging. Borrowing techniques from the structured case, it’s shown
that the odd-even decomposition can significantly reduce reconstruction error while maintaining a constant
memory footprint. This results in novel particle hierarchies and optimal traversal heuristics that outperform
traditional approaches in progressive decoding quality-cost trade-offs.
2023 journal paper
Progressive Tree-Based Compression of Large-Scale Particle Data
Scientific simulations and observations using particles have been creating large datasets that require
effective and efficient data reduction to store, transfer, and analyze. However, current approaches either
compress only small data well while being inefficient for large data, or handle large data but with
insufficient compression. Toward effective and scalable compression/decompression of particle positions, we
introduce new kinds of particle hierarchies and corresponding traversal orders that quickly reduce
reconstruction error while being fast and low in memory footprint. Our solution to compression of large-scale
particle data is a flexible block-based hierarchy that supports progressive, random-access, and error-driven
decoding, where error estimation heuristics can be supplied by the user. For low-level node encoding, we
introduce new schemes that effectively compress both uniform and densely structured particle distributions.

2022 conference paper
High-Quality Progressive Alignment of Large 3D Microscopy Data
Large-scale three-dimensional (3D) microscopy acquisitions fre-quently create terabytes of image data at high
resolution and magni-fication. Imaging large specimens at high magnifications requires acquiring 3D
overlapping image stacks as tiles arranged on a two-dimensional (2D) grid that must subsequently be aligned
and fused into a single 3D volume. Due to their sheer size, aligning many overlapping gigabyte-sized 3D tiles
in parallel and at full resolution is memory intensive and often I/O bound. Current techniques trade accuracy
for scalability, perform alignment on subsampled images, and require additional postprocess algorithms to
refine the alignment quality, usually with high computational requirements. One common solution to the memory
problem is to subdivide the overlap region into smaller chunks (sub-blocks) and align the sub-block pairs in
parallel, choosing the pair with the most reliable alignment to determine the global transformation. Yet
aligning all sub-block pairs at full resolution remains computationally expensive. The key to quickly
developing a fast, high-quality, low-memory solution is to identify a single or a small set of sub-blocks that
give good alignment at full resolution without touching all the overlapping data. In this paper, we present a
new iterative approach that leverages coarse resolution alignments to progressively refine and align only the
promising candidates at finer resolutions, thereby aligning only a small user-defined number of sub-blocks at
full resolution to determine the lowest error transformation between pairwise overlapping tiles. Our
progressive approach is 2.6x faster than the state of the art, requires less than 450MB of peak RAM (per
parallel thread), and offers a higher quality alignment without the need for additional postprocessing
refinement steps to correct for alignment errors.

2022 journal paper
AMM: Adaptive Multilinear Meshes
★ Best Paper Award at PacificVis 2022
Adaptive representations are increasingly indispensable for reducing the in-memory and on-disk footprints of
large-scale data.
Usual solutions are designed broadly along two themes: reducing data precision, e.g. , through compression, or
adapting data resolution, e.g. , using spatial hierarchies.
Recent research suggests that combining the two approaches, i.e. , adapting both resolution and precision
simultaneously, can offer significant gains over using them individually.
However, there currently exist no practical solutions to creating and evaluating such representations at
scale.
In this work, we present a new resolution-precision-adaptive representation to support hybrid data reduction
schemes and offer an interface to existing tools and algorithms.
Through novelties in spatial hierarchy, our representation, Adaptive Multilinear Meshes (AMM), provides
considerable reduction in the mesh size.
AMM creates a piecewise multilinear representation of uniformly sampled scalar data and can selectively relax
or enforce constraints on conformity, continuity, and coverage, delivering a flexible adaptive representation.
AMM also supports representing the function using mixed-precision values to further the achievable gains in
data reduction.
We describe a practical approach to creating AMM incrementally using arbitrary orderings of data and
demonstrate AMM on six types of resolution and precision datastreams.
By interfacing with state-of-the-art rendering tools through VTK, we demonstrate the practical and
computational advantages of our representation for visualization techniques.
With an open-source release of our tool to create AMM, we make such evaluation of data reduction accessible to
the community, which we hope will foster new opportunities and future data reduction schemes.
2021 conference paper
High-Quality and Low-Memory-Footprint Progressive Decoding of
Large-scale Particle Data
Large-scale Particle Data
IEEE Symposium on Large Data Analysis and Visualization (LDAV)
★ Best Paper Honorable Mention
Particle representations are used often in large-scale simulations and observations, frequently
creating datasets containing several millions of particles or more.
Due to their sheer size, such datasets are difficult to store, transfer, and analyze efficiently.
Data compression is a promising solution; however, effective approaches to compress particle data
are lacking and no community-standard and accepted techniques exist.
Current techniques are designed either to compress small data very well but require high
computational resources when applied to large data, or to work with large data but without a focus
on compression, resulting in low reconstruction quality per bit stored.
In this paper, we present innovations targeting tree-based particle compression approaches that
improve the tradeoff between high quality and low memory-footprint for compression and decompression
of large particle datasets.
Inspired by the lazy wavelet transform, we introduce a new way of partitioning space, which allows a
low-cost depth-first traversal of a particle hierarchy to cover the space broadly.
We also devise novel data-adaptive traversal orders that significantly reduce reconstruction error
compared to traditional data-agnostic orders such as breadth-first and depth-first traversals.
The new partitioning and traversal schemes are used to build novel particle hierarchies that can be
traversed with asymptotically constant memory footprint while incurring low reconstruction error.
Our solution to encoding and decoding of large particle data is a flexible block-based hierarchy
that supports progressive, random-access, and error-driven decoding, where error heuristics can be
supplied by the user.
Through extensive experimentation, we demonstrate the efficacy and the flexibility of the proposed
techniques when combined as well as when used independently with existing approaches on a wide range
of scientific particle datasets.

2021 conference paper
Load-Balancing Parallel I/O of
Compressed Hierarchical Layouts
Compressed Hierarchical Layouts
IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC)
Scientific phenomena are being simulated at ever-increasing resolution and fidelity thanks to
advances in modern supercomputers.
These simulations produce a deluge of data, putting unprecedented demand on the end-to-end
data-movement pipeline that consists of parallel writes for checkpoint and analysis dumps and
parallel localized reads for exploratory analysis and visualization tasks.
Parallel I/O libraries are often optimized for uniformly distributed large-sized accesses, whereas
reads for analysis and visualization benefit from data layouts that enable random-access and
multiresolution queries.
While multiresolution layouts enable interactive exploration of massive datasets, efficiently
writing such layouts in parallel is challenging, and straightforward methods for creating a
multiresolution hierarchy can lead to inefficient memory and disk access.
In this paper, we propose a compressed, hierarchical layout that facilitates efficient parallel
writes, while being efficient at serving random access, multiresolution read queries for post-hoc
analysis and visualization.
To efficiently write data to such a layout in parallel is challenging due to potential
load-balancing issues at both the data transformation and disk I/O steps.
Data is often not readily distributed in a way that facilitates efficient transformations necessary
for creating a multiresolution hierarchy.
Further, when compression or data reduction is applied, the compressed data chunks may end up with
different sizes, confounding efficient parallel I/O.
To overcome both these issues, we present a novel two-phase load-balancing strategy to optimize both
memory and disk access patterns unique to writing non-uniform multiresolution data.
We implement these strategies in a parallel I/O library and evaluate the efficacy of our approach by
using real-world simulation data and a novel approach to microbenchmarking on the Theta
Supercomputer of Argonne National Laboratory.
2021 journal paper, presented at IEEE VIS 2020
Efficient and Flexible Hierarchical
Data Layouts for a Unified Encoding of
Scalar Field Precision and Resolution
Data Layouts for a Unified Encoding of
Scalar Field Precision and Resolution
To address the problem of ever-growing scientific data sizes making data movement a major hindrance
to analysis, we introduce a novel encoding for scalar fields: a unified tree of resolution and
precision, specifically constructed so that valid cuts correspond to sensible approximations of the
original field in the precision-resolution space.
Furthermore, we introduce a highly flexible encoding of such trees that forms a parameterized family
of data hierarchies.
We discuss how different parameter choices lead to different trade-offs in practice, and show how
specific choices result in known data representation schemes such as ZFP, IDX, and JPEG2000.
Finally, we provide system-level details and empirical evidence on how such hierarchies facilitate
common approximate queries with minimal data movement and time, using real-world data sets ranging
from a few gigabytes to nearly a terabyte in size.
Experiments suggest that our new strategy of combining reductions in resolution and precision is
competitive with state-of-the-art compression techniques with respect to data quality, while being
significantly more flexible and orders of magnitude faster, and requiring significantly reduced
resources.
2019 journal paper, presented at IEEE VIS 2018
A Study of the Trade-off Between
Reducing Precision and Reducing Resolution
for Data Analysis and Visualization
Reducing Precision and Reducing Resolution
for Data Analysis and Visualization
There currently exist two dominant strategies to reduce data sizes in analysis and visualization: reducing the
precision of the data, e.g., through quantization, or reducing its resolution, e.g., by subsampling.
Both have advantages and disadvantages and both face fundamental limits at which the reduced information
ceases to be useful.
The paper explores the additional gains that could be achieved by combining both strategies.
In particular, we present a common framework that allows us to study the trade-off in reducing precision
and/or resolution in a principled manner.
We represent data reduction schemes as progressive streams of bits and study how various bit orderings such as
by resolution, by precision, etc., impact the resulting approximation error across a variety of data sets as
well as analysis tasks.
Furthermore, we compute streams that are optimized for different tasks to serve as lower bounds on the
achievable error.
Scientific data management systems can use the results presented in this paper as guidance on how to store and
stream data to make efficient use of the limited storage and bandwidth in practice.
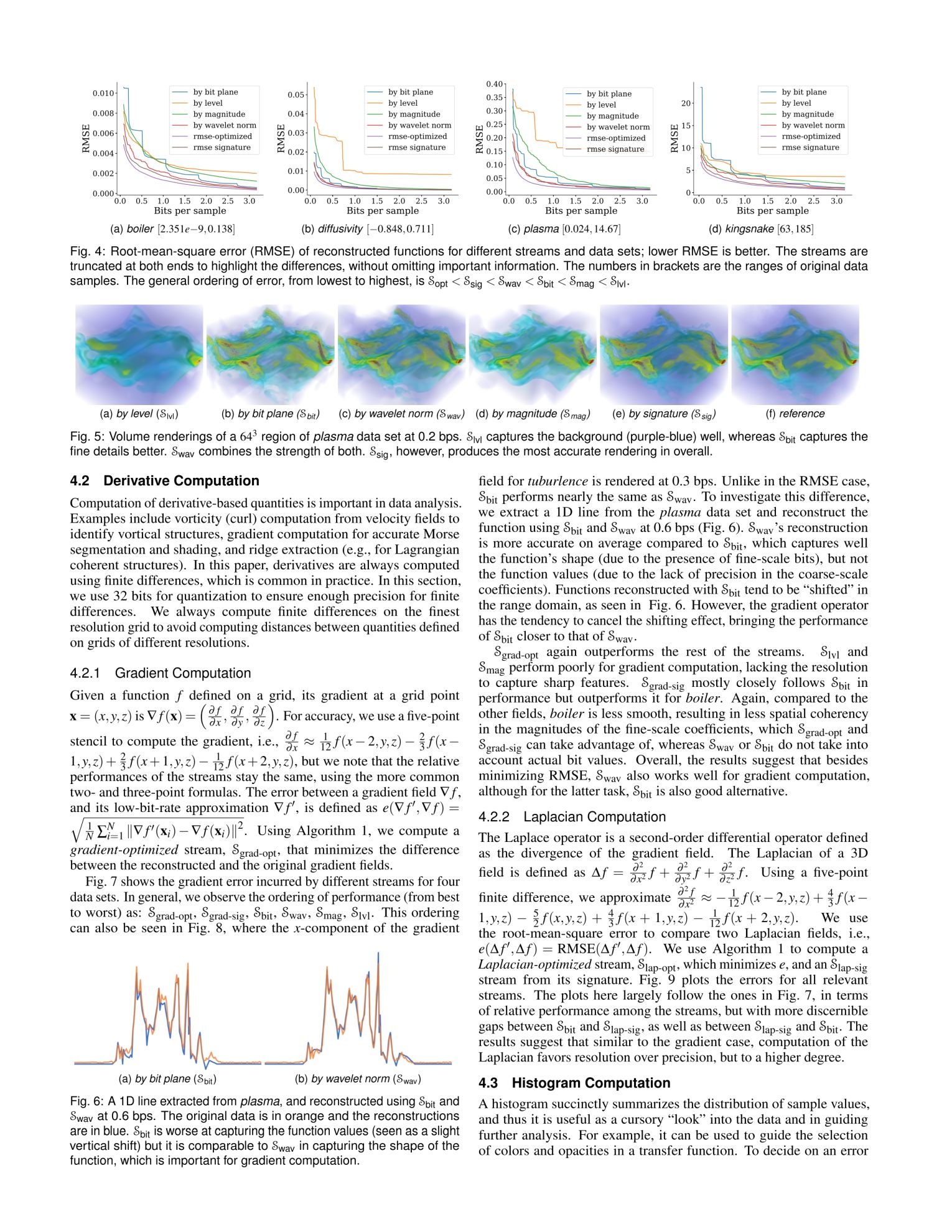
2017 conference poster
Accelerating In-situ Feature Extraction
of Large-Scale Combustion Simulation
with Subsampling
of Large-Scale Combustion Simulation
with Subsampling
The increasing gap between available compute power and I/O capabilities is driving more users to adopt in-situ
processing capabilities.
However, making the transition from post-processing to in-situ mode is challenging, as parallel analysis
algorithms do not always scale well with the actual simulation code.
This is observed because these algorithms either involve global reduction operations with significant
communication overheads or have to perform an overwhelmingly large amount of computation.
In this work we propose a software stack, designed specially to expedite parallel analysis algorithms, thus
making it possible for them to work in in-situ mode.
Our software stack comprises of data-reduction techniques, sub-sampling and compression, used to reduce the
computation load of the analysis algorithm.
For better approximation of data, we can also use wavelets instead of sub sampling. We demonstrate the
efficacy of our pipeline using two analysis algorithms, parallel merge tree and isosurface rendering.
We also study the trade-offs between the I/O gains and the corresponding error induced by the data reduction
techniques.
We present results with KARFS simulation framework run on the Tesla cluster of the Scientific computing and
Imaging institute at the University of Utah.
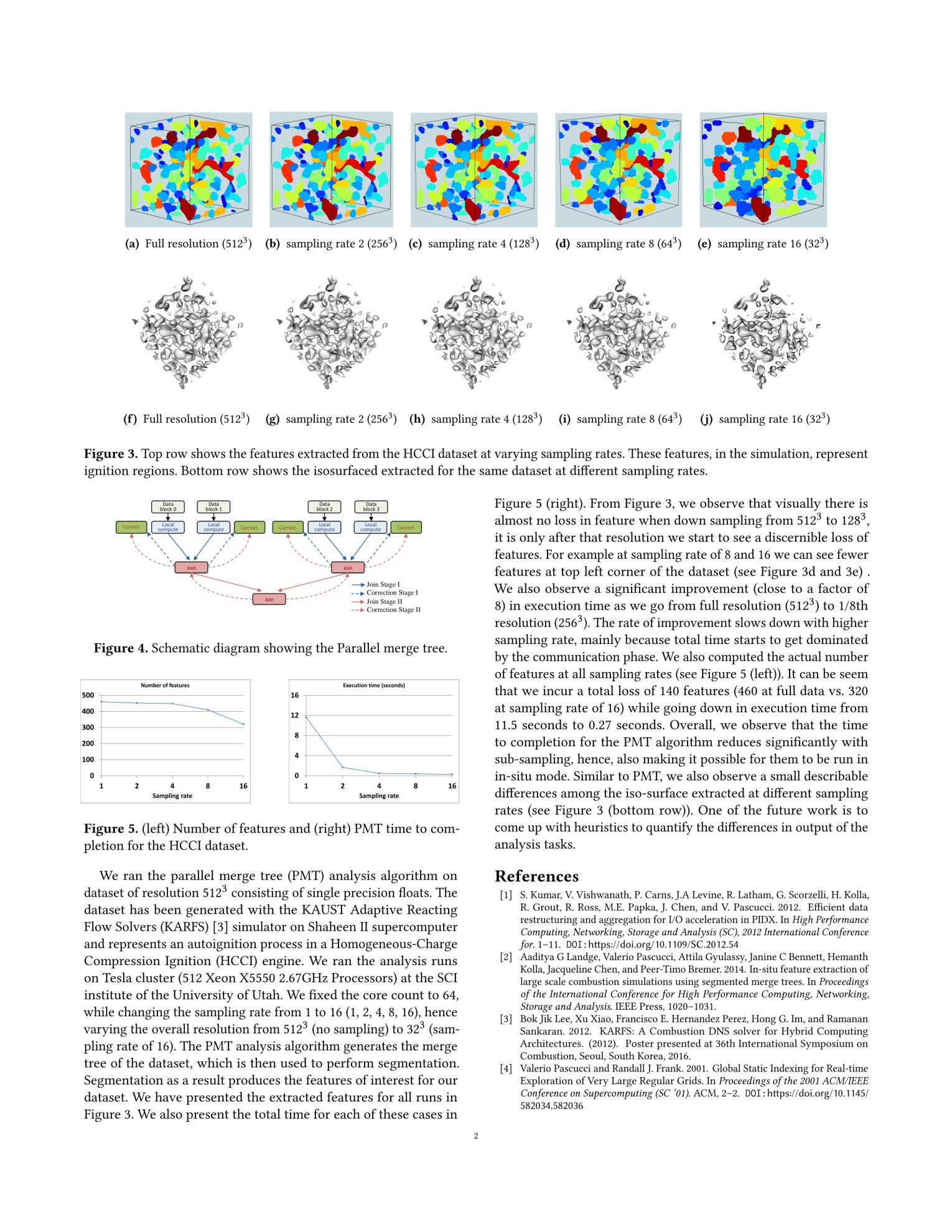
2017 conference paper
Reducing Network Congestion and Synchronization Overhead During
Aggregation of Hierarchical Data
Aggregation of Hierarchical Data
Hierarchical data representations have been shown to be effective tools for coping with large-scale scientific
data.
Writing hierarchical data on supercomputers, however, is challenging as it often involves all-to-one
communication during aggregation of low-resolution data which tends to span the entire network domain,
resulting in several bottlenecks.
We introduce the concept of indexing templates, which succinctly describe data organization and can be used to
alter movement of data in beneficial ways.
We present two techniques, domain partitioning and localized aggregation, that leverage indexing templates to
alleviate congestion and synchronization overheads during data aggregation.
We report experimental results that show significant I/O speedup using our proposed schemes on two of today’s
fastest supercomputers, Mira and Shaheen II, using the Uintah and S3D simulation frameworks.
2016 conference poster
Visualizing Publication Data
IEEE Visualization Conference (VIS)
Best Project 2015 - University of Utah’s CS-5630 (Visualization)
PubVis is an interactive tool to visualize connections between papers published over multiple years in a
collection of papers.
It provides users with a multi-faceted way to explore research topics of interest, spot their trends over
time, and find high-impact papers and influential authors on the topics.
Navigation is done through following citation relationships and shared-keyword relationships among papers, as
well as collaboration relationships among authors.
PubVis’s strength lies in its light abstraction model and ease of interaction, while being able to present a
large amount of information to users at once.

2015 technical report
Interactive Analysis of Large Combustion
Simulation Datasets on Commodity Hardware
Simulation Datasets on Commodity Hardware
Technical report
Recent advances in high performance computing have enabled large scale scientific simulations that produce
massive amounts of data, often on the order of terabytes or even petabytes.
Analysis of such data on desktop workstations is difficult and often limited to only small subsets of the data
or coarse resolutions yet can still be extremely time-consuming.
Alternatively, one must resort to big computing clusters which are not easily available, difficult to program
and with software often not flexible enough to provide custom, scalable analyses.
Here we present a use case from turbulent combustion where scientist are interested in studying, for example,
the heat release rate of turbulent flames in a simulation totaling more than 5.5 TB of data.
This requires a non-trivial processing pipeline of extracting iso-surfaces, tracing lines normal to the
surface and integrating the heat release for all 660 time steps to accumulate histograms and time curves.
Using existing tools, this analysis even at reduced resolution, takes days and is thus rarely performed.
Instead, we present a novel application based on light-weight streaming processing and fast multi-resolution
disk accesses that enables this analysis to be done interactively using commodity hardware.
In particular, our system allows scientist to immediately explore all parameters involved in the process, i.e.
iso-values, integration lengths, etc., providing unprecedented analysis capabilities.
Our application has already led to a number of interesting insights.
For example, our results suggest using an adaptive iso-value and integration length for each time steps would
lead to more accurate results.
The new approach replaces a traditional batch-processing work flow, and provides a new paradigm in scientific
discovery through interactive analysis of large simulation data.

2013 conference paper
Control of Rotational Dynamics
for Ground Behaviors
for Ground Behaviors
I improved the paper's rendering system to add per-pixel lighting and ambient occlusion, which greatly
improves realism, by highlighting ground contact shadows for the various rolling motions in this paper.
I also ran experiments, and helped render some of the results for the paper.
This paper proposes a physics-based framework to generate rolling behaviors with significant rotational
components.
The proposed technique is a general approach for guiding coordinated action that can be layered over existing
control architectures through the purposeful regulation of specific whole-body features.
Namely, we apply control for rotation through the specification and execution of specific desired 'rotation
indices' for whole-body orientation, angular velocity and angular momentum control.
We account for the stylistic components of behaviors through reference posture control.
The novelty of the described work includes control over behaviors with considerable rotational components as
well as a number of characteristics useful for general control, such as flexible posture tracking and contact
control planning.

2012 journal paper
Detail-Preserving Controllable Deformation from Sparse Examples
This is the journal extension of a conference paper.
I wrote all the code required to run new experiments, corrected flawed data, and generated the new results in
this paper.
I also implemented a new inverse kinematics method to reduce the number of input markers for training bone
deformations, making the training faster.
Recent advances in laser scanning technology have made it possible to faithfully scan a real object with tiny
geometric details, such as pores and wrinkles.
However, a faithful digital model should not only capture static details of the real counterpart but also be
able to reproduce the deformed versions of such details.
In this paper, we develop a data-driven model that has two components; the first accommodates smooth
large-scale deformations and the second captures high-resolution details.
Large-scale deformations are based on a nonlinear mapping between sparse control points and bone
transformations.
A global mapping, however, would fail to synthesize realistic geometries from sparse examples, for highly
deformable models with a large range of motion.
The key is to train a collection of mappings defined over regions locally in both the geometry and the pose
space.
Deformable fine-scale details are generated from a second nonlinear mapping between the control points and
per-vertex displacements.
We apply our modeling scheme to scanned human hand models, scanned face models, face models reconstructed from
multiview video sequences, and manually constructed dinosaur models.
Experiments show that our deformation models, learned from extremely sparse training data, are effective and
robust in synthesizing highly deformable models with rich fine features, for keyframe animation as well as
performance-driven animation.
We also compare our results with those obtained by alternative techniques.

2012 technical report
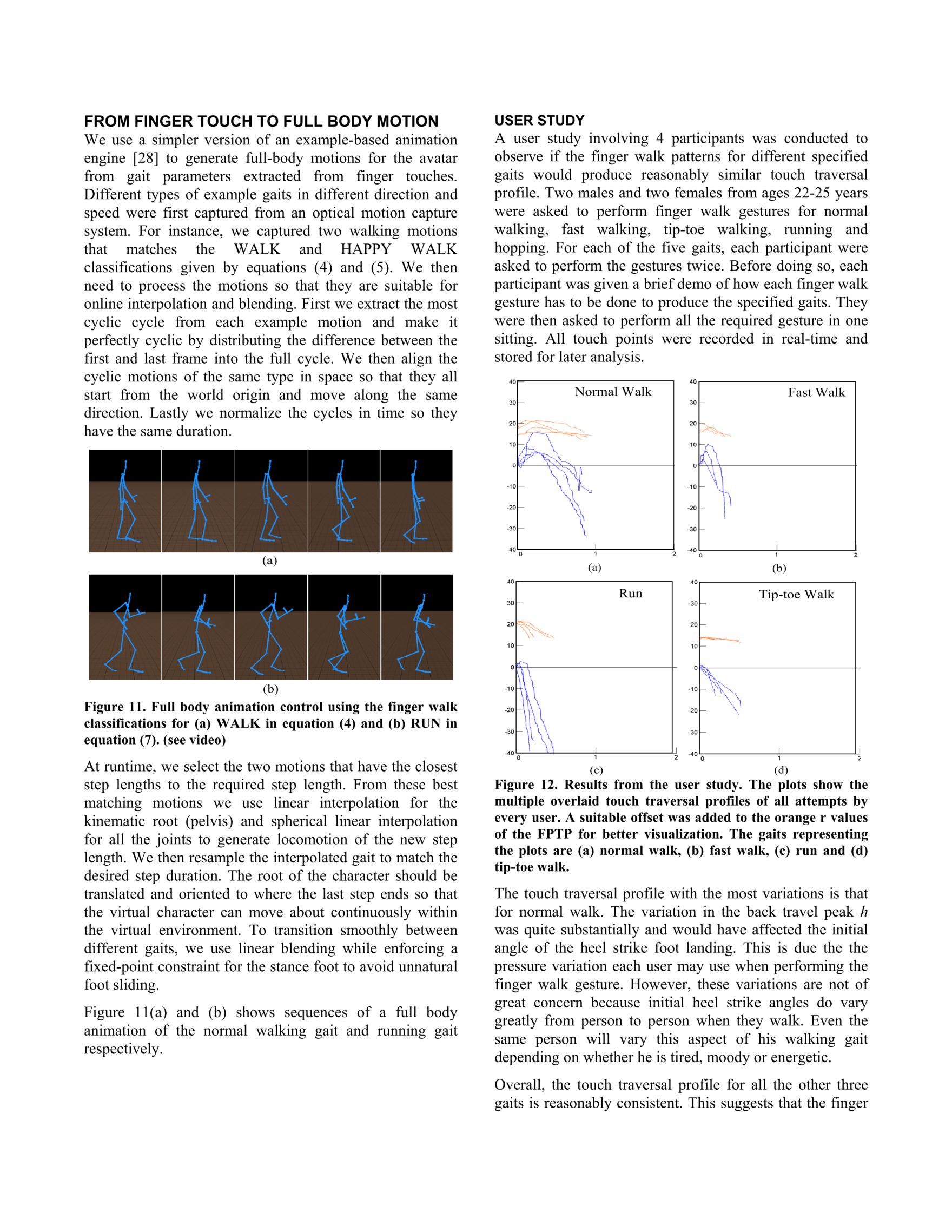
FingerWalk: Controlling Human Gait Animation using Finger Walk
on a Multi-touch Surface
on a Multi-touch Surface
Technical report
This paper proposes analyzing finger touches on a conventional tablet computer to support locomotion control
of virtual characters.
Although human finger movements and leg movements are not fully equivalent kinematically and dynamically, we
can successfully extract intended gait parameters from finger touches to drive virtual avatars to locomote in
different styles.
User studies with 4 participants show that their finger pattern walk for different gaits such as variants of
walking (normal, fast, tip-toe) and running do not show significant variations in temporal profiles.
This suggests that the finger walk gestures on multi-touch tablets may have the potential for more universal
adoption as a convenient means for end users to control gait nuances of their avatar as they navigate in
virtual worlds and interact with other avatars.
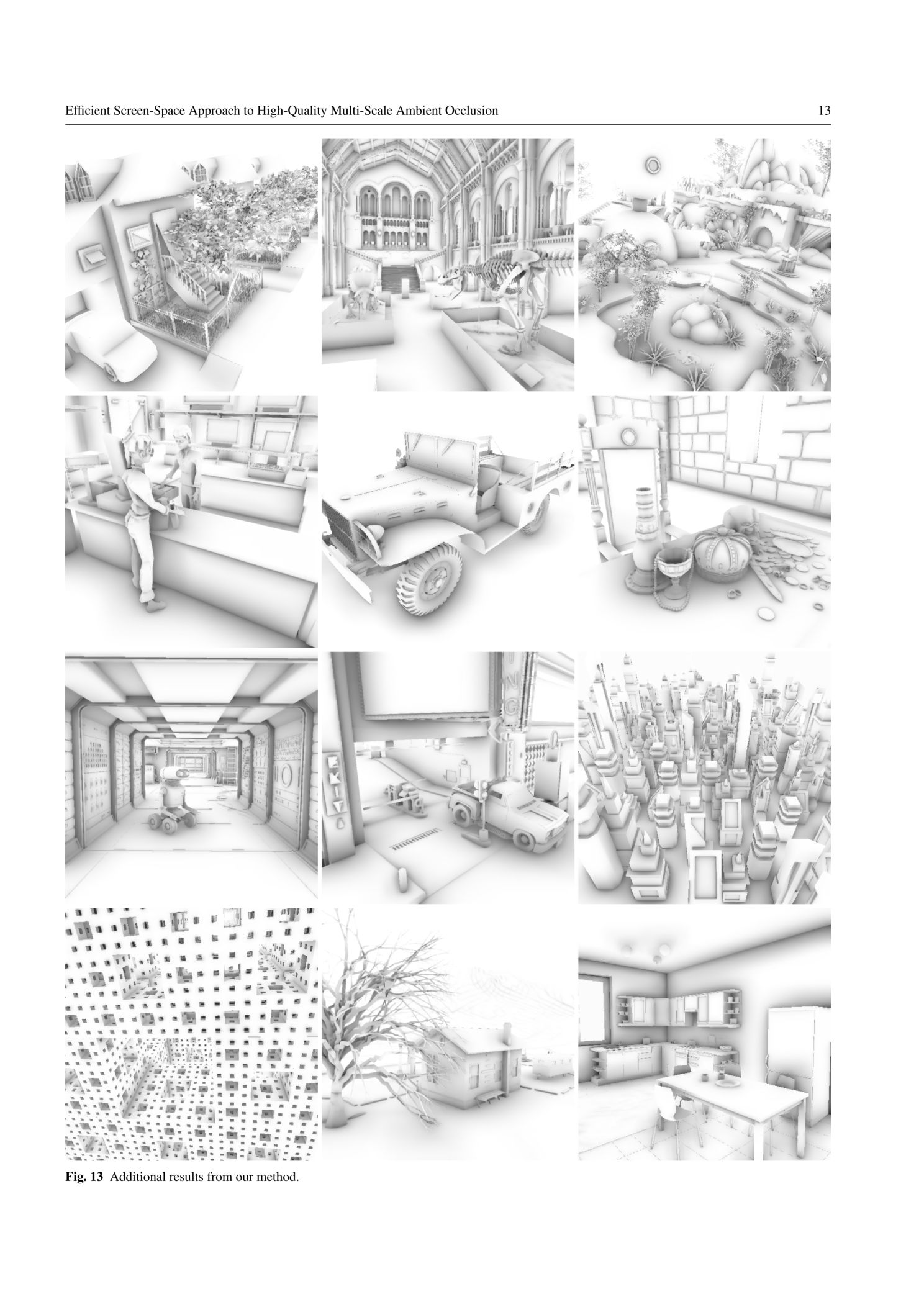
2012 journal paper, extended version of the MSSAO CGI'11 paper below
Efficient Screen-Space Approach to
High-Quality Multiscale Ambient Occlusion
High-Quality Multiscale Ambient Occlusion
We present a new screen-space ambient occlusion (SSAO) algorithm that improves on the state-of-the-art SSAO
methods in both performance and quality.
Our method computes ambient occlusion (AO) values at multiple image resolutions and combines them to obtain
the final, high-resolution AO value for each image pixel.
It produces high-quality AO that includes both high-frequency shadows due to nearby, occluding geometry and
low-frequency shadows due to distant geometry.
Our approach only needs to use very small sampling kernels at every resolution, thereby achieving high
performance without resorting to random sampling.
As a consequence, our results do not suffer from noise and excessive blur, which are common of other SSAO
methods.
Therefore, our method also avoid the expensive, final blur pass commonly used in other SSAO methods.
The use of multiple resolutions also helps reduce errors that are caused by SSAO’s inherent lack of visibility
checking.
Temporal incoherence caused by using coarse resolutions is solved with an optional temporal filtering pass.
Our method produces results that are closer to ray-traced solutions than those of any existing SSAO method’s,
while running at similar or higher frame rates than the fastest ones.
2011 conference paper
Multi-Resolution Screen-Space
Ambient Occlusion
Ambient Occlusion
We present a new screen-space ambient occlusion (SSAO) algorithm that improves on the state-of-the-art SSAO
methods in both speed and image quality.
Our method computes ambient occlusion (AO) for multiple image resolutions and combines them to obtain the
final high-resolution AO.
It produces high-quality AO that includes details from small local occluders to low-frequency occlusions from
large faraway occluders.
This approach allows us to use very small sampling kernels at every resolution, and thereby achieve high
performance without resorting to random sampling, and therefore our results do not suffer from noise and
excessive blur, which are common of SSAO.
We use bilateral upsampling to interpolate lower-resolution occlusion values to prevent blockiness and
occlusion leaks.
Compared to existing SSAO methods, our method produces results closer to ray-traced solutions, while running
at comparable or higher frame rates than the fastest SSAO method.

2010 conference poster
Real-Time CSG Rendering
Using Fragment Sort
Using Fragment Sort
We present a simple ray casting method to render a CSG product term.
The primitives are input as polygon meshes.
Our method uses the programmability on modern graphics hardware to capture at each pixel the depth values of
all the primitives’ surfaces.
By sorting these surface fragments in front-to-back order, we are able to find the CSG result at each pixel.
Our method does not maintain additional fragment information, and deferred shading is used for the final
rendering of the CSG result.
Our method is general in that there is no special handling needed for intersection and subtraction operations,
and non-convex primitives are treated equally as convex primitives.
