
2019
Support Vector Machines
These are my handwritten notes that explain the basics of Support Vector Machines (SVM), which are supervised learning models with associated learning algorithms that analyze data for classification and regression analysis.

2018
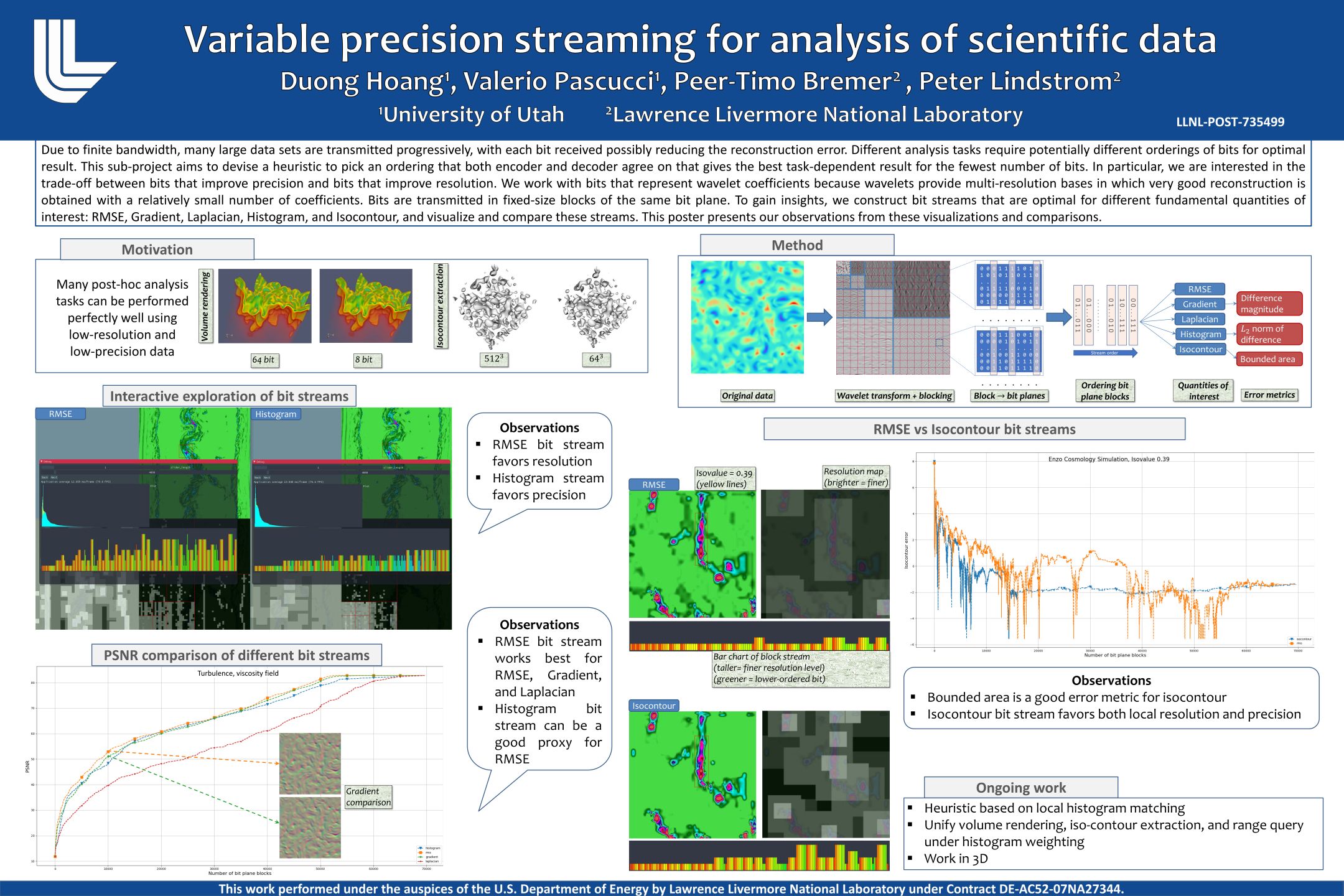
Adaptive Precision-Resolution Streaming
for Scientific Data Visualization and Analysis
for Scientific Data Visualization and Analysis
★ Best Student Poster 2017
These are posters and slides of talks that I gave at the Center for Applied Scientific Computing, Lawrence Livermore National Laboratory during my internships there from 2015 to 2018 on the topic of "data optimal streaming".
My work was part of the Variable Precision Computing LDRD project.
Lossy data compression has been proven useful in reducing significantly the costs of data movements while maintaining high data quality.
Each class of visualization and analysis tasks however imposes a different set of requirements on the quality of input data in terms of discretization and quantization levels.
This project develops compression algorithms and data structures that allow progressive refinements in both resolution and precision, thereby achieving the best approximation for a given bit budget.
We aim to design "data-optimal" data representations and algorithms, where only the necessary bits from a large dataset are progressively fetched and transmitted to perform a scientific task at hand.
The main approach was to combine "resolution-based" reduction techniques such as various multiresolution schemes (IDX, wavelets) with "precision-based" reduction techniques (ZFP) to achieve better data reduciton than either type of techniques alone.
I also studied the trade-offs between reducing resolution and reducing precision for various analysis tasks.
From this work, I have published a few peer-reviewed papers.
2016
Approximate Nearest Neighbors
This is a summary of the paper Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality by Indyk and Motwani.
Given a set of n points P in X = Rd, the nearest-neighbor (NN) problem is to find a point p in P that is closest to a query point q.
This problem is of importance to many applications involving similarity searching such as data compression, databases and data mining, information retrieval, image and video databases, machine learning, pattern recognition, and statistics and data analysis.
Suffering from the curse of dimensionality, existing algorithms either have query time linear in n and d, or have query time sub-linear in n and polynomial in d but exponential preprocessing cost nd, making them infeasible for a large d (e.g., d ≥ 100) which is common in practice.
It is observed that insisting on the absolute nearest neighbor is often an overkill, due to the heuristical nature of the use of distance metric and the selection of features in practice.
Therefore the paper in discussion aims to solve an approximate relaxation to nearest neighbor problem, namely the ϵ-nearest neighbor problem (ϵ-NN): to find a point p ∈ P that is an ϵ-approximate nearest neighbor of the query q, in that ∀p′ ∈ P, d(p, q) ≤ (1+ϵ)d(p′, q).

2015
Differential Topology and Morse Theory
These are my handwritten notes I was taking a differential topology lecture series that Professor Valerio Pascucci gave in KAUST.
The notes are "incomplete" since the lecture series had to conclude earlier than expected.

2014
Understanding Basic Concepts in Radiometry
Radiometry is a theoretical foundation for physically-based rendering algorithms.
It is a measurement of electromagnetic energy (of visible light in particular), and measures spatial (and angular) properties of light.
Use ray optics, hence largely a geometrical subject.
These slides:
- Provide an intuitive understanding of flux, irradiance, radiance
- Provide an intuitive understanding of reflection functions (BRDF)
- Point out common pitfalls of thinking, or sources of confusion along the way
- Short digressions into somewhat related topics

2011
A Type and Effect System for Atomicity
In this report, we summarize and analyze the PLDI 2003 paper A Type and Effect System for Atomicity by Flanagan and Qadeer.
We show that while this paper is the first to use static analysis to successfully verify a fundamental correctness property in multithreaded programs that is atomicity, its approach has limitations that should be, and indeed have been, addressed in future work.
There have been strong beliefs in recent years that parallel computing is the future for computing. As a consequence, multicore machines, and multithreaded software that can take advantage of such machines, have becoming increasingly more popular. Compared to serial programs, multithreaded programs are harder to test and debug. The main reason is that the interleaving of threads results in many complex execution scenarios and makes synchronization bugs non-deterministic, thus hard to reproduce and fix. One common source of bugs in parallel programs is race condition, where more than one threads try to access a shared variable simultaneously, and at least one of the accesses is a write. There have been works trying to detect race conditions using a variety of techniques. However, Flanagan and Qadeer argue that the absence of race conditions is neither necessary nor sufficient for a program to be correct. They advocate checking for a stronger non-interference property called atomicity, where atomic methods can be assumed to execute in “one step”, without interferences of methods from other threads. To that end, the authors propose a type system to specify and verify the atomicity of methods in multithreaded Java programs. They show that their approach successfully finds atomicity violations in the JDK’s codebase that can lead to crashes. This report elaborates more on the importance of atomicity, and discusses race conditions and atomicity in a larger context. We also give reasons to justify the use of a type system instead of other static analysis techniques. In the same spirit, we states the advantages and disadvantages of the static analysis approach taken by this paper compared with other methods such as dynamic analysis and model checking used in later papers. Finally, we explain in detail and give examples to illustrate the limitations of the proposed type system when verifying atomicity in practice.
There have been strong beliefs in recent years that parallel computing is the future for computing. As a consequence, multicore machines, and multithreaded software that can take advantage of such machines, have becoming increasingly more popular. Compared to serial programs, multithreaded programs are harder to test and debug. The main reason is that the interleaving of threads results in many complex execution scenarios and makes synchronization bugs non-deterministic, thus hard to reproduce and fix. One common source of bugs in parallel programs is race condition, where more than one threads try to access a shared variable simultaneously, and at least one of the accesses is a write. There have been works trying to detect race conditions using a variety of techniques. However, Flanagan and Qadeer argue that the absence of race conditions is neither necessary nor sufficient for a program to be correct. They advocate checking for a stronger non-interference property called atomicity, where atomic methods can be assumed to execute in “one step”, without interferences of methods from other threads. To that end, the authors propose a type system to specify and verify the atomicity of methods in multithreaded Java programs. They show that their approach successfully finds atomicity violations in the JDK’s codebase that can lead to crashes. This report elaborates more on the importance of atomicity, and discusses race conditions and atomicity in a larger context. We also give reasons to justify the use of a type system instead of other static analysis techniques. In the same spirit, we states the advantages and disadvantages of the static analysis approach taken by this paper compared with other methods such as dynamic analysis and model checking used in later papers. Finally, we explain in detail and give examples to illustrate the limitations of the proposed type system when verifying atomicity in practice.

2010
A Survey of Three DHT Systems:
CAN, Pastry, and Chord
CAN, Pastry, and Chord
One of the key problems in P2P is efficient lookup.
Given a key, we want to locate the nodes that store the data associated with the key.
A system that provides that hash-table-like service is called a distributed hash table (DHT).
In this report, we study three early, notable DHT systems out of the many that have been proposed in recent years, namely CAN [1], Pastry [2], and Chord [3].
We look at how each of them solve the basic lookup problem, compare their performances and scalabilities, and assess them with regards to important criteria such as load balancing, data availability, and robustness.
Along the way, we also comment on their shortcomings and propose possible research directions to overcome those drawbacks.
